Nesse post não vou explicar as várias outras funcionalidades que a API oferece em relação aos loops. Aqui vou fazer uma pausa para testar o que foi explicado até agora. De que adianta a teoria sem um teste prático do que tá rolando?
Para testar um loop distribuído, resolvi criar uma função que calcula a multiplicação entre duas matrizes, colocando o resultado em uma terceira matriz (MC = MA * MB):
const int MATRIX_SIZE = 1000;
int MA[MATRIX_SIZE][MATRIX_SIZE];
int MB[MATRIX_SIZE][MATRIX_SIZE];
int MC[MATRIX_SIZE][MATRIX_SIZE];
void multi()
{
int soma;
//percorre cada linha de MA
for(int j = 0; j < MATRIX_SIZE; j++)
{
//percorre cada coluna de MB
for(int i = 0; i < MATRIX_SIZE; i++, soma = 0)
{
//calcula
for(int k = 0; k < MATRIX_SIZE; k++)
{
soma += MA[j][k] * MB[k][i];
}
//coloca resoltado na matriz MC
MC[j][i] = soma;
}
}
}
int main(int ac, char **av)
{
multi();
return 0;
}Como o teste consiste em melhorar o desempenho do cálculo, não me dei ao trabalho de iniciar os elementos das matrizes e nem de verificar se o resultado está correto.
Executando o código anterior, o Code::Blocks retornou a mensagem:
Process returned 0 (0×0) execution time : 23.509 s
Press any key to continue.
Lembrando que executei a compilação debug sem nenhum tipo de otimização. Com certeza a release seria muito mais rápida.
Quem lembra das aulas de matemática do colegial, sabe que o cálculo de cada elemento resultante (MC) independe do cálculo de elementos anteriores. O laço for está de acordo com as restrições impostas pela API, então, pq não dividir a tarefa em várias threads?
const int MATRIX_SIZE = 1000;
int MA[MATRIX_SIZE][MATRIX_SIZE];
int MB[MATRIX_SIZE][MATRIX_SIZE];
int MC[MATRIX_SIZE][MATRIX_SIZE];
void multi()
{
//percorre cada linha de MA
#pragma omp parallel for
for(int j = 0; j < MATRIX_SIZE; j++)
{
//percorre cada coluna de MB
for(int i = 0; i < MATRIX_SIZE; i++)
{
int soma = 0;
//calcula
for(int k = 0; k < MATRIX_SIZE; k++)
{
soma += MA[j][k] * MB[k][i];
}
//coloca resoltado na matriz MC
MC[j][i] = soma;
}
}
}
int main(int ac, char **av)
{
multi();
return 0;
}Repare que, além do #pragma omp parallel for adicionado antes do primeiro loop, outras mudanças foram feitas para adaptar o código:
- A variável soma foi removida do começo da função e declarada dentro do segundo for, para evitar que seja compartilhada entre as threads;
- Não é mais necessário zerar a variável soma no corpo do segundo for;
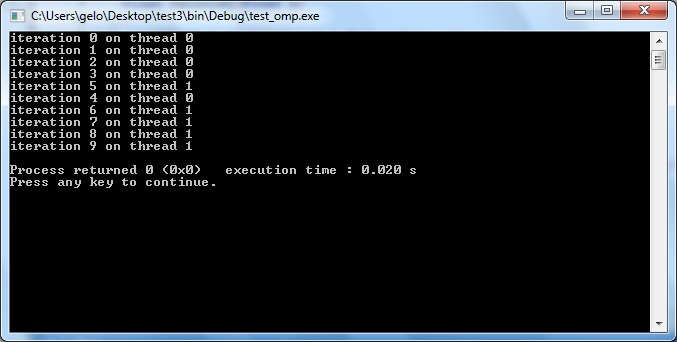
Executando o código modificado, obtive o seguinte resultado:
Process returned 0 (0×0) execution time : 7.129 s
Press any key to continue.
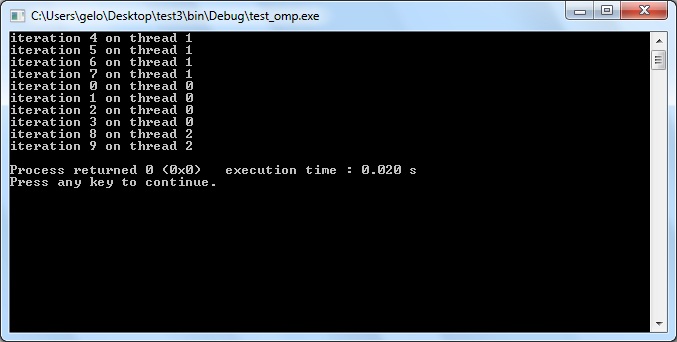
Isso corresponde a, praticamente, um terço do tempo necessário para calcular pelo método tradicional. Surpreso? Requisitando 20 threads para executar o loop, obtive um resultado melhor ainda:
Process returned 0 (0×0) execution time : 6.692 s
Press any key to continue.
Okay, a diferença não é gritante, mas num sistema onde o desempenho é um fator crítico, esses ms podem fazer toda a diferença.









 3.17 KB
3.17 KB 76.9 KB
76.9 KB


{kind=link}
Recent Comments