No post Programação Multicore com OpenMP, mostrei como fazer a API funcionar no Code::Blocks, compilando um exemplo simples que executa um trecho de código em várias threads, ou seja, nada muito útil.
Agora que vc já conseguiu compilar o “Hello World” do primeiro post, vamos fazer bom uso do processamento distribuído nos nossos laços da repetição.
Primeiramente, vc deve entender que, na programação com OpenMP, temos variáveis (parte da memória) compartilhadas e privates.
Quê?!
leitor perdido
No exemplo abaixo, a variável a é visível para todas as threads que executarão a tarefa do bloco. Já a variável b possui uma cópia exclusiva em cada thread, ou seja, cada thread possui sua variável b.
void some_function()
{
int a = 0;
#pragma omp parallel
{
int b = 1;
}
}Okay, entendi… e daí?
leitor não impressionado
Por enquanto, leve em conta que saber disso pode evitar várias dores de cabeça.
Usando OpenMP nos laços de repetição
Para tal operação, definimos a seguinte linha antes do nosso for:
#pragma omp parallel forFicando assim:
#pragma omp parallel for
for(int i = 0; i < 10; i++)
{
printf("iteration %d on thread %d\n", i, omp_get_thread_num());
}O resultado é:
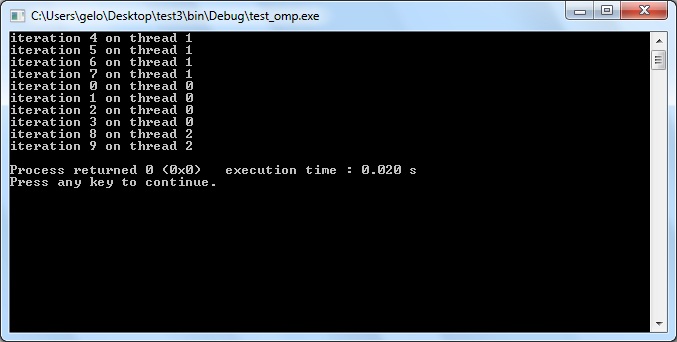
Nesse exemplo, as iterações do for serão divididas em várias threads (na minha execução, 3 threads). O número de threads corresponde ao número padrão ou o valor que vc definiu com omp_set_num_threads(num_threads). Para não ter o trabalho de chamar a função em cada parte do código que vc deseja alterar o número de threads, a seguinte sintaxe é permitida:
#pragma omp parallel for num_threads(NUM_THREADS)Onde NUM_THREADS corresponde ao número de threads que devem executar a tarefa.
Se o exemplo anterior for modificado para:
#pragma omp parallel for num_threads(2)
for(int i = 0; i < 10; i++)
{
printf("iteration %d on thread %d\n", i, omp_get_thread_num());
}Então o loop vai ser dividido em, no máximo, duas threads como mostra o resultado:
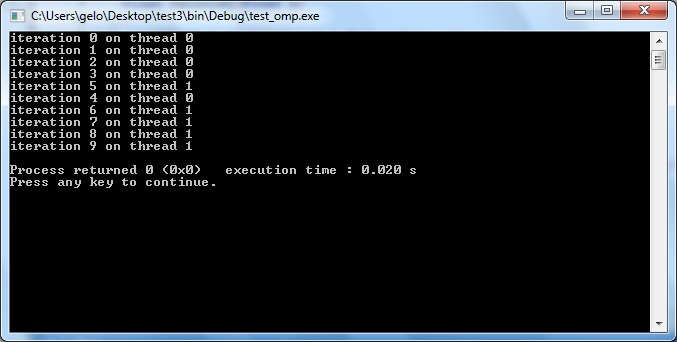
Como podemos notar, apenas as threads de ID 0 e 1 executam o for.
Repare que as iterações não são executadas em ordem, então leve em conta que se uma iteração depende de outra, como na soma de médias num vetor de alunos, por exemplo (existe um jeito de fazer isso, vou explicar mais pra frente), vc terá problemas.
A API OpenMP impõe as seguintes restrições no uso de loops paralelos:
- A variável que controla o loop (no caso anterior, i) deve ser do tipo signed integer;
- A operação de comparação no corpo for deve ser do tipo loop_variable <, <=, >, >= integer_invariável;
- A terceira expressão do corpo for deve ser do tipo que incrementa (x++) ou decrementa (x- -);
- Se a operação de comparação usar os operadores < ou <=, então a variável de controle deve ser incrementada a cada iteração. No caso contrário, se forem utilizados os operadores > ou >=, então a variável de controle deve ser decrementada a cada iteração;
- O loop deve consistir em um único bloco de código, sem jumps (goto, por exemplo) para fora do loop. Como exceção, podemos usar exit() que finaliza a aplicação e não apenas a thread em questão. Caso vc utilize um break ou goto, esses devem levar a algum lugar DENTRO do loop e não fora. O mesmo vale para exceptions, que devem ser tratadas dentro do loop e não fora dele;
Para deixar mais claro aquele conceito de memória compartilhada e private, temos o exemplo abaixo que não é válido, pois a variável temp é compartilhada por todas as threads, ou seja, enquanto a thread de ID 0 escreve um valor X e espera ler esse valor algumas instruções adiante, a thread de ID 1 escreve um valor Y no mesmo endereço de memória:
int a[4] = {1, 2, 4, 8};
int temp;
#pragma omp parallel for
for(int i = 0; i < 4; i++)
{
temp = a[i];
}Para um resultado correto, o ideal seria declarar a variável temp dentro do laço for:
int a[4] = {1, 2, 4, 8};
#pragma omp parallel for
for(int i = 0; i < 4; i++)
{
int temp;
temp = a[i];
}Reductions
Nos permite compartilhar uma variável sem que sua integridade seja comprometida pela concorrência entre threads. Veja o exemplo:
int notas[10] = {7, 4, 8, 3, 6, 9, 10, 1, 2, 5};
int soma = 0;
#pragma omp parallel for
for(int i = 0; i < 10; i++)
{
soma += notas[i];
}
printf("soma = %d\n", soma);Não podemos garantir que a soma seja 55, pois todas as threads estão usando a mesma variável. Criar um lock? Não é necessário, pois a API nos permite fazer da seguinte forma:
int notas[10] = {7, 4, 8, 3, 6, 9, 10, 1, 2, 5};
int soma = 0;
#pragma omp parallel for reduction(+:soma)
for(int i = 0; i < 10; i++)
{
soma += notas[i];
}
printf("soma = %d\n", soma);Nos bastidores, o OpenMP cria uma variável private soma para cada thread e, ao final, soma todas e coloca o valor na variável compartilhada (global) soma. Então vc pode ter certeza que o valor de soma é o esperado.
As outras operações disponíveis são:
- + (adição): a variável private inicia com o valor 0;
- – (subtração): a variável private inicia com o valor 0;
- * (multiplicação): a variável private inicia com o valor 1;
- & (operador AND): a variável private inicia com o valor ~0;
- | (operador OR): a variável private inicia com o valor 0;
- ^ (operador OR exclusivo): a variável private inicia com o valor 0;
- && (operador condicional AND): a variável private inicia com o valor 1;
- || (operador condicional OR): a variável private inicia com o valor 0;
A segunda parte eu deixo para outro post.
Leave a Reply